A one-way ANOVA is used to determine whether or not there is a statistically significant difference between the means of three or more independent groups.
This type of test is called a one-way ANOVA because we are analyzing how one predictor variable impacts a response variable.
Note: If we were instead interested in how two predictor variables impact a response variable, we could conduct a two-way ANOVA.
How to Conduct a One-Way ANOVA in R
The following example illustrates how to conduct a one-way ANOVA in R.
Background
Suppose we want to determine if three different exercise programs impact weight loss differently. The predictor variable we’re studying is exercise program and the response variable is weight loss, measured in pounds.
We can conduct a one-way ANOVA to determine if there is a statistically significant difference between the resulting weight loss from the three programs.
We recruit 90 people to participate in an experiment in which we randomly assign 30 people to follow either program A, program B, or program C for one month.
The following code creates the data frame we’ll be working with:
#make this example reproducible
set.seed(0)
#create data frame
data
#view first six rows of data frame
head(data)
# program weight_loss
#1 A 2.6900916
#2 A 0.7965260
#3 A 1.1163717
#4 A 1.7185601
#5 A 2.7246234
#6 A 0.6050458
The first column in the data frame shows the program that the person participated in for one month and the second column shows the total weight loss that person experienced by the end of the program, measured in pounds.
Exploring the Data
Before we even fit the one-way ANOVA model, we can gain a better understanding of the data by finding the mean and standard deviation of weight loss for each of the three programs using the dplyr package:
#load dplyr package library(dplyr) #find mean and standard deviation of weight loss for each treatment group data %>% group_by(program) %>% summarise(mean = mean(weight_loss), sd = sd(weight_loss)) # A tibble: 3 x 3 # program mean sd # #1 A 1.58 0.905 #2 B 2.56 1.24 #3 C 4.13 1.57
We can also create a boxplot for each of the three programs to visualize the distribution of weight loss for each program:
#create boxplots
boxplot(weight_loss ~ program,
data = data,
main = "Weight Loss Distribution by Program",
xlab = "Program",
ylab = "Weight Loss",
col = "steelblue",
border = "black")
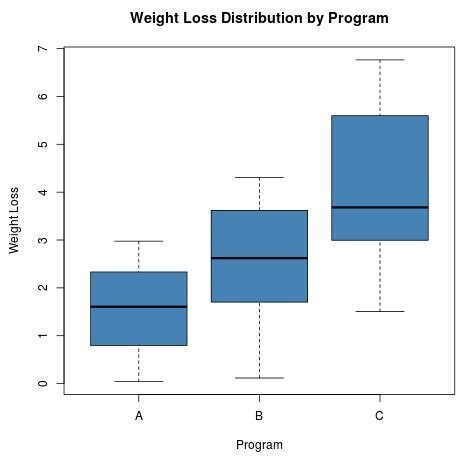
Just from these boxplots we can see that the the mean weight loss is highest for the participants in Program C and the mean weight loss is lowest for the participants in Program A.
We can also see that the standard deviation (the “length” of the boxplot) for weight loss is quite a bit higher in Program C compared to the other two programs.
Next, we’ll fit the one-way ANOVA model to our data to see if these visual differences are actually statistically significant.
Fitting the One-Way ANOVA Model
The general syntax to fit a one-way ANOVA model in R is as follows:
aov(response variable ~ predictor_variable, data = dataset)
In our example, we can use the following code to fit the one-way ANOVA model, using weight_loss as the response variable and program as our predictor variable. We can then use the summary() function to view the output of our model:
#fit the one-way ANOVA model
model #view the model output
summary(model)
# Df Sum Sq Mean Sq F value Pr(>F)
#program 2 98.93 49.46 30.83 7.55e-11 ***
#Residuals 87 139.57 1.60
#---
#Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
From the model output we can see that the predictor variable program is statistically significant at the .05 significance level.
In other words, there is a statistically significant difference between the mean weight loss that results from the three programs.
Checking the Model Assumptions
Before we go any further, we should check to see that the assumptions of our model are met so that the our results from the model are reliable. In particular, a one-way ANOVA assumes:
1. Independence – the observations in each group need to be independent of each other. Since we used a randomized design (i.e. we assigned participants to the exercise programs randomly), this assumption should be met so we don’t need to worry too much about this.
2. Normality – the dependent variable should be approximately normally distributed for each level of the predictor variable.
3. Equal Variance – the variances for each group are equal or approximately equal.
One way to check the assumptions of normality and equal variance is to use the function plot(), which produces four model-checking plots. In particular, we are most interested in the following two plots:
- Residuals vs Fitted – this plot shows the relationship between the residuals and the fitted values. We can use this plot to roughly gauge whether or not the variance between the groups is approximately equal.
- Q-Q Plot – this plot displays the standardized residuals against the theoretical quantiles. We can use this plot to roughly gauge whether or not the normality assumption is met.
The following code can be used to produce these model-checking plots:
plot(model)
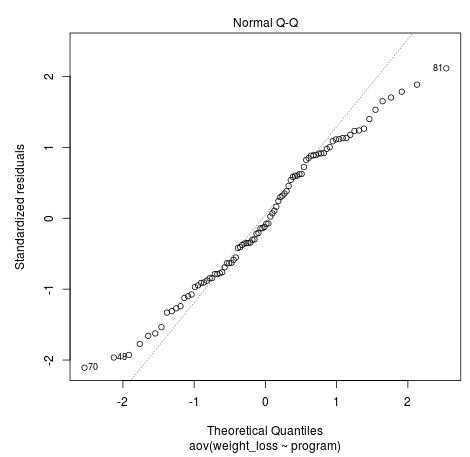
The Q-Q plot above allows us to check the normality assumption. Ideally the standardized residuals would fall along the straight diagonal line in the plot. However, in the plot above we can see that the residuals stray from the line quite a bit towards the beginning and the end. This is an indication that our normality assumption may be violated.
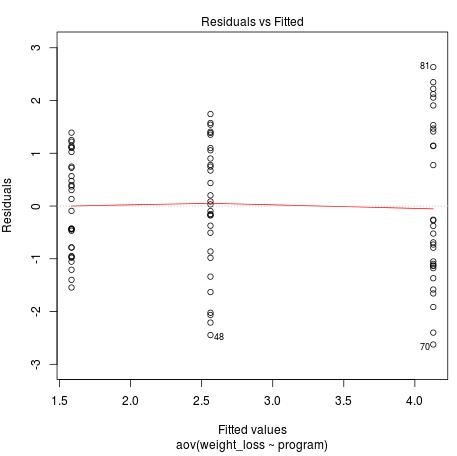
The Residuals vs Fitted plot above allows us to check our equal variances assumption. Ideally we’d like to see the residuals be equally spread out for each level of the fitted values.
We can see that the residuals are much more spread out for the higher fitted values, which is an indication that our equal variances assumption may be violated.
To formally test for equal variances, we could Levene’s Test using the car package:
#load car package library(car) #conduct Levene's Test for equality of variances leveneTest(weight_loss ~ program, data = data) #Levene's Test for Homogeneity of Variance (center = median) # Df F value Pr(>F) #group 2 4.1716 0.01862 * # 87 #--- #Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
The p-value of the test is 0.01862. If we use a 0.05 significance level, we would reject the null hypothesis that the variances are equal across the three programs. However, if we use a 0.01 significance level, we would not reject the null hypothesis.
Although we could attempt to transform the data to make sure that our assumptions of normality and equality of variances are met, at the time being we won’t worry too much about this.
Analyzing Treatment Differences
Once we have verified that the model assumptions are met (or reasonably met), we can then conduct a post hoc test to determine exactly which treatment groups differ from one another.
For our post hoc test, we will use the function TukeyHSD() to conduct Tukey’s Test for multiple comparisons:
#perform Tukey's Test for multiple comparisons
TukeyHSD(model, conf.level=.95)
# Tukey multiple comparisons of means
# 95% family-wise confidence level
#
#Fit: aov(formula = weight_loss ~ program, data = data)
#
#$program
# diff lwr upr p adj
#B-A 0.9777414 0.1979466 1.757536 0.0100545
#C-A 2.5454024 1.7656076 3.325197 0.0000000
#C-B 1.5676610 0.7878662 2.347456 0.0000199
The p-value indicates whether or not there is a statistically significant difference between each program. We can see from the output that there is a statistically significant difference between the mean weight loss of each program at the 0.05 significance level.
We can also visualize the 95% confidence intervals that result from the Tukey Test by using the plot(TukeyHSD()) function in R:
#create confidence interval for each comparison
plot(TukeyHSD(model, conf.level=.95), las = 2)
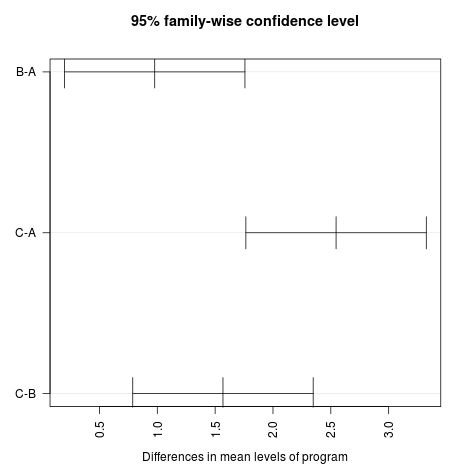
The results of the confidence intervals are consistent with the results of the hypothesis tests.
In particular, we can see that none of the confidence intervals for the mean weight loss between programs contain the value zero, which indicates that there is a statistically significant difference in mean loss between all three programs.
This is consistent with the fact that all of the p-values from our hypothesis tests are below 0.05.
Reporting the Results of the One-Way ANOVA
Lastly, we can report the results of the one-way ANOVA in such a way that summarizes the findings:
A one-way ANOVA was conducted to examine the effects of exercise program on weight loss (measured in pounds). There was a statistically significant difference between the effects of the three programs on weight loss (F(2, 87) = 30.83, p = 7.55e-11). Tukey’s HSD post hoc tests were carried out.
The mean weight loss for participants in program C is significantly higher than the mean weight loss for participants in program B (p
The mean weight loss for participants in program C is significantly higher than the mean weight loss for participants in program A (p
In addition, the mean weight loss for participants in program B is significantly higher than the mean weight loss for participants in program A (p = 0.01).
Additional Resources
The following tutorials provide additional information about one-way ANOVA’s:
An Introduction to One-Way ANOVA
A Guide to Using Post Hoc Tests with ANOVA
The Complete Guide: How to Report ANOVA Results