The best way to understand a dataset is to calculate descriptive statistics for the variables within the dataset. There are three common forms of descriptive statistics:
1. Summary statistics – Numbers that summarize a variable using a single number. Examples include the mean, median, standard deviation, and range.
2. Tables – Tables can help us understand how data is distributed. One example is a frequency table, which tells us how many data values fall within certain ranges.
3. Graphs – These help us visualize data. An example would be a histogram.
This tutorial explains how to calculate descriptive statistics for variables in SPSS.
Example: Descriptive Statistics in SPSS
Suppose we have the following dataset that contains four variables for 20 students in a certain class:
- Exam score
- Hours spent studying
- Prep exams taken
- Current grade in the class
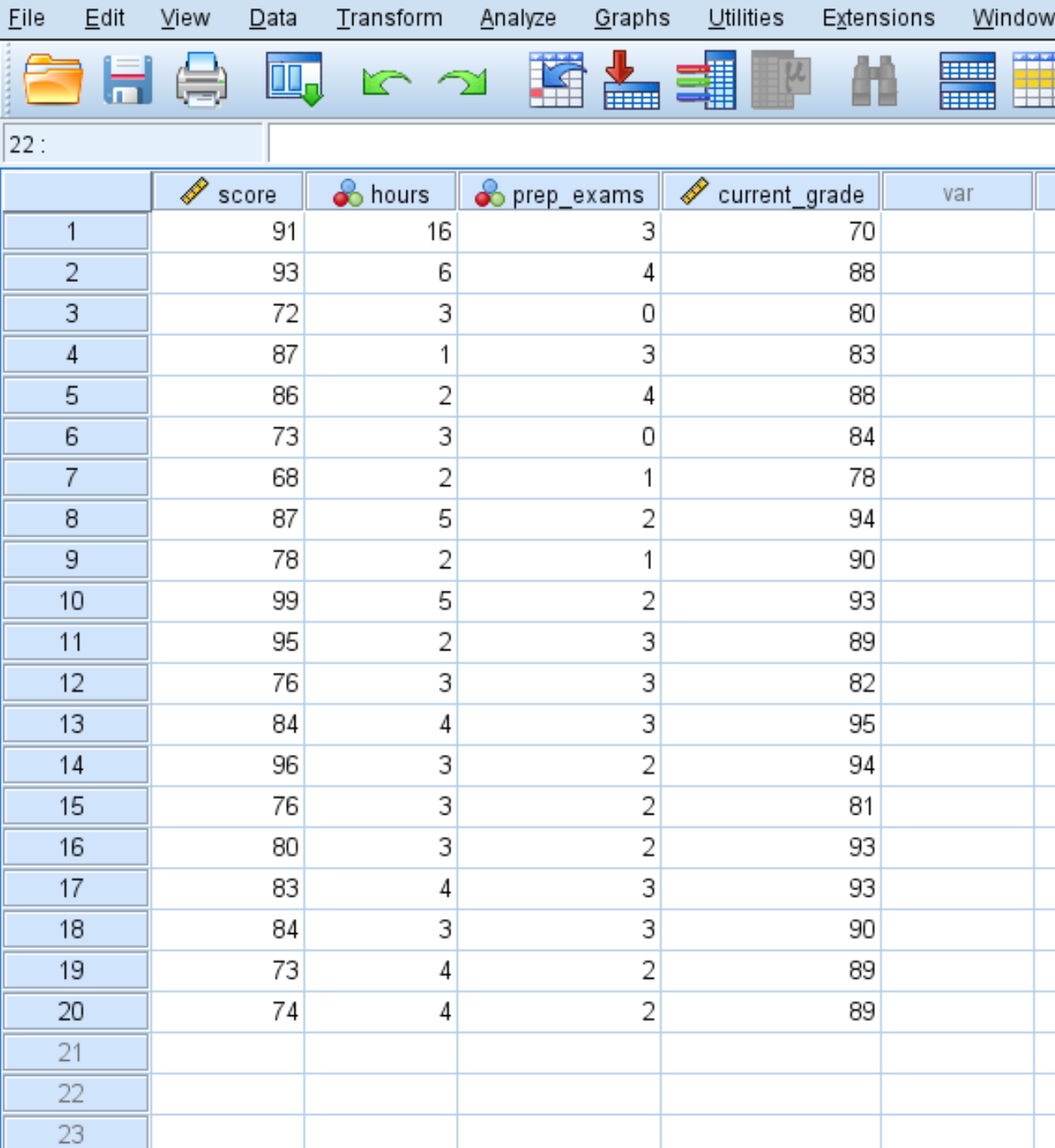
Here is how to calculate descriptive statistics for each of these four variables:
Summary Statistics
To calculate summary statistics for each variable, click the Analyze tab, then Descriptive Statistics, then Descriptives:
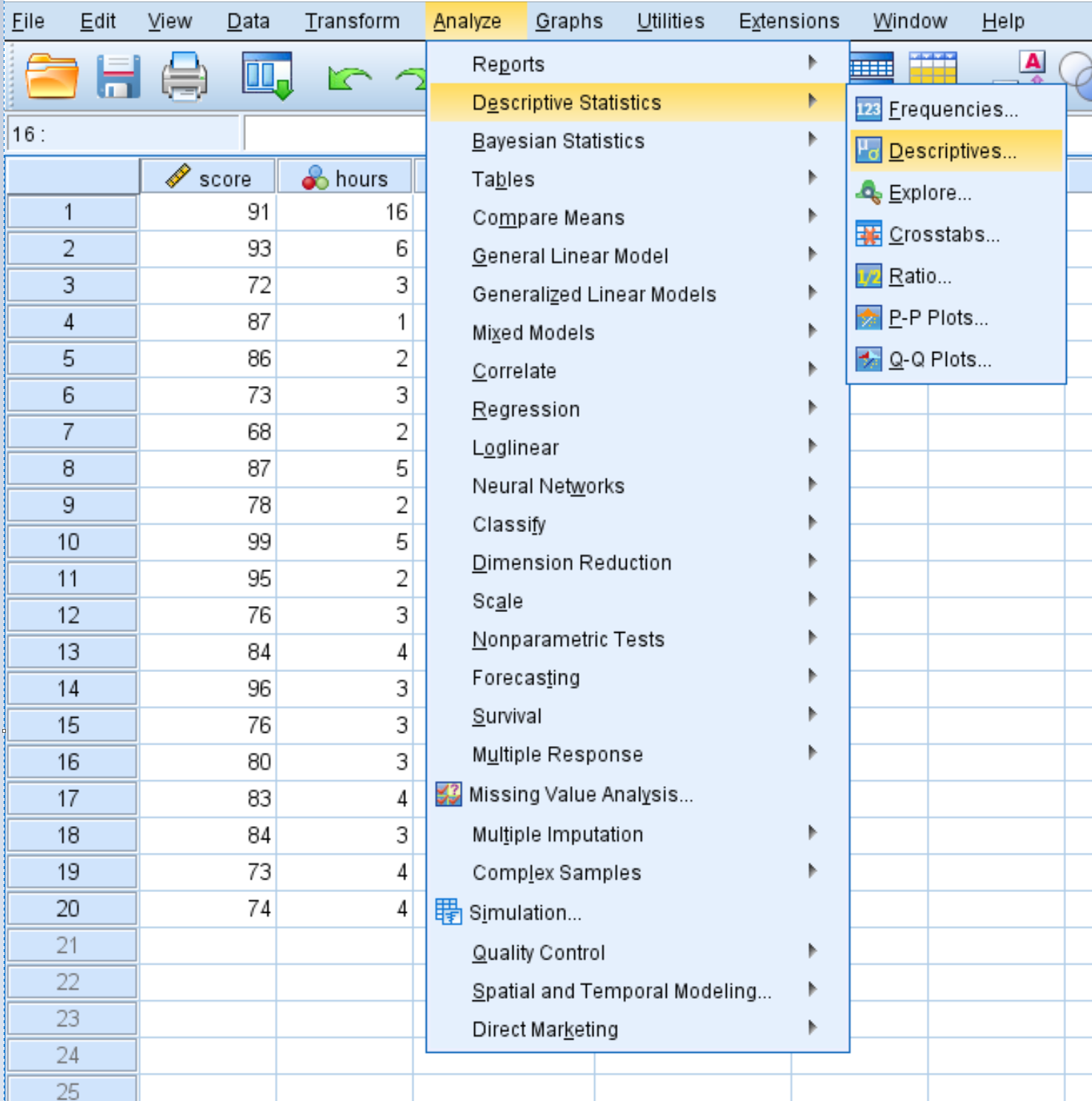
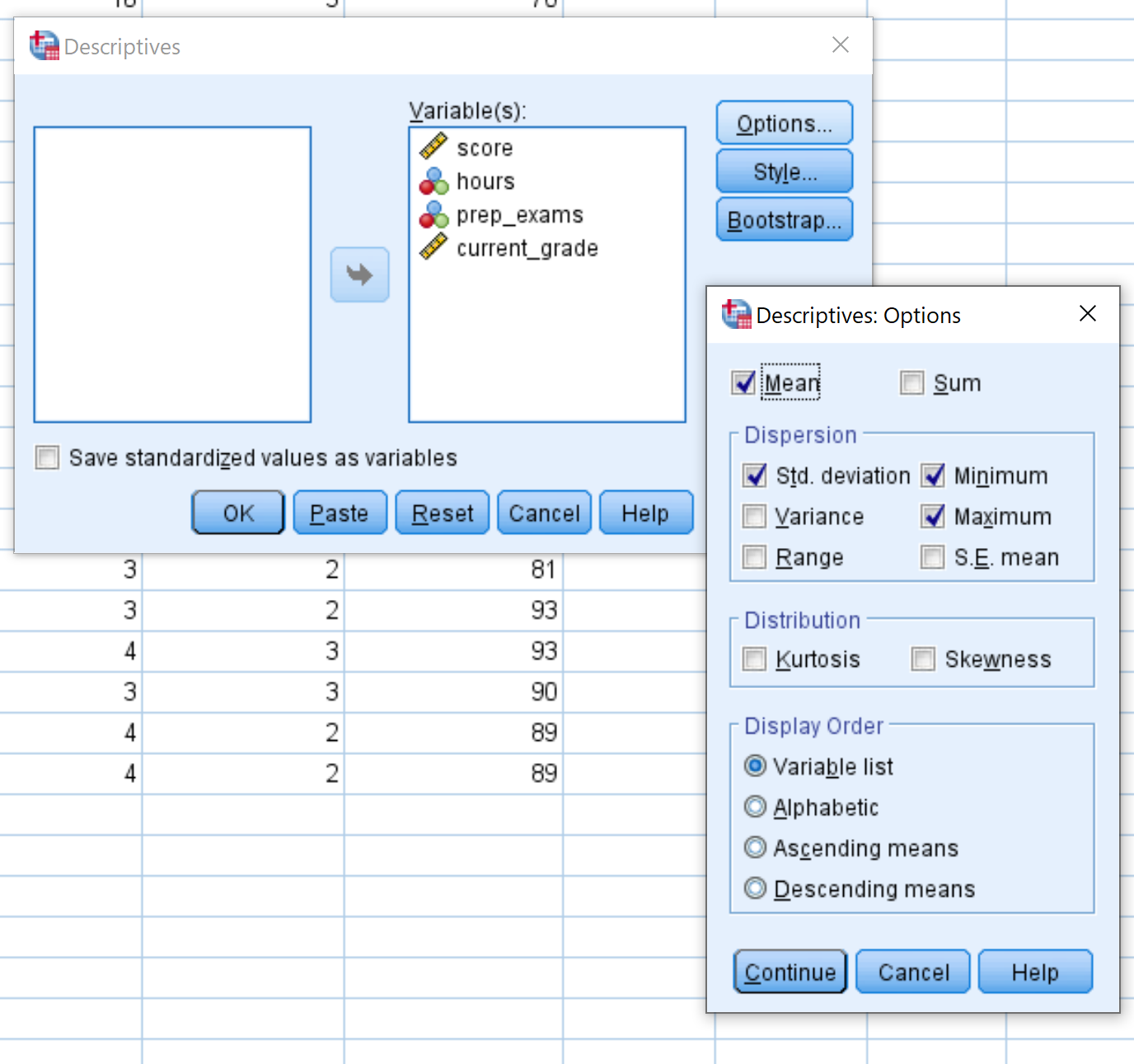
In the new window that pops up, drag each of the four variables into the box labelled Variable(s). If you’d like, you can click the Options button and select the specific descriptive statistics you’d like SPSS to calculate. Then click Continue. Then click OK.
Once you click OK, a table will appear that displays the following descriptive statistics for each variable:
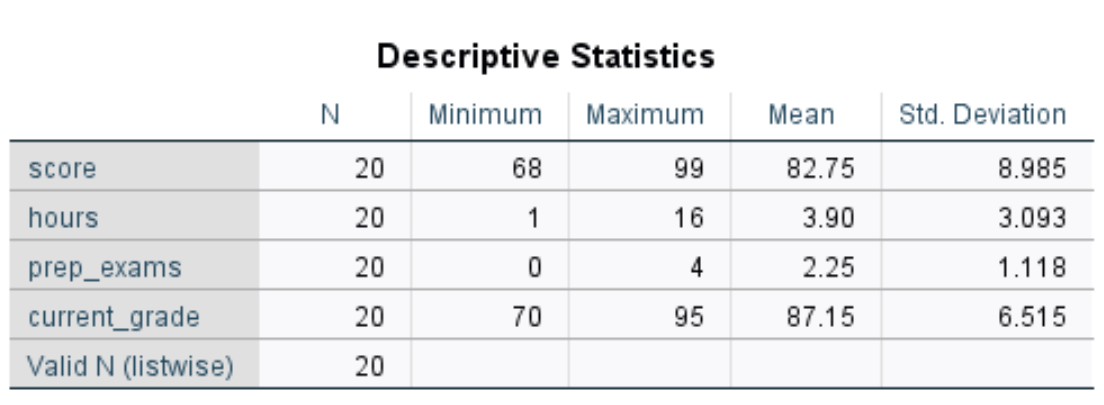
Here is how to interpret the numbers in this table for the variable score:
- N: The total number of observations. In this case there are 20.
- Minimum: The minimum value for exam score. In this case it’s 68.
- Maximum: The maximum value for exam score. In this case it’s 99.
- Mean: The mean exam score. In this case it’s 82.75.
- Std. Deviation: The standard deviation in exam scores. In this case it’s 8.985.
This table allows us to quickly understand the range of each variable (using the minimum and maximum), the central location of each variable (using the mean), and how spread out the values are for each variable (using the standard deviation).
Tables
To produce a frequency table for each variable, click the Analyze tab, then Descriptive Statistics, then Frequencies.
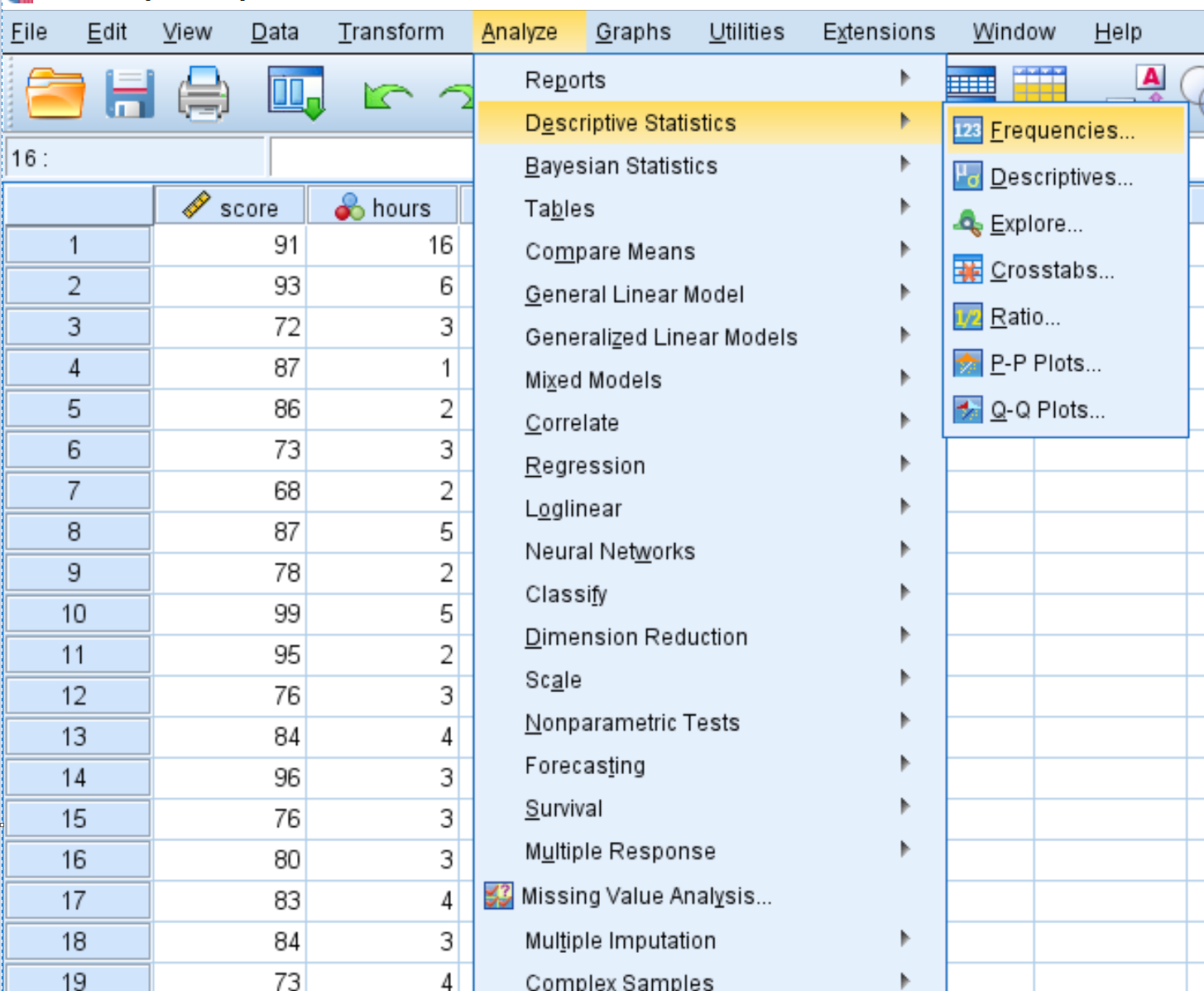
In the new window that pops up, drag each variable into the box labelled Variable(s). Then click OK.
A frequency table for each variable will appear. For example, here’s the one for the variable hours:
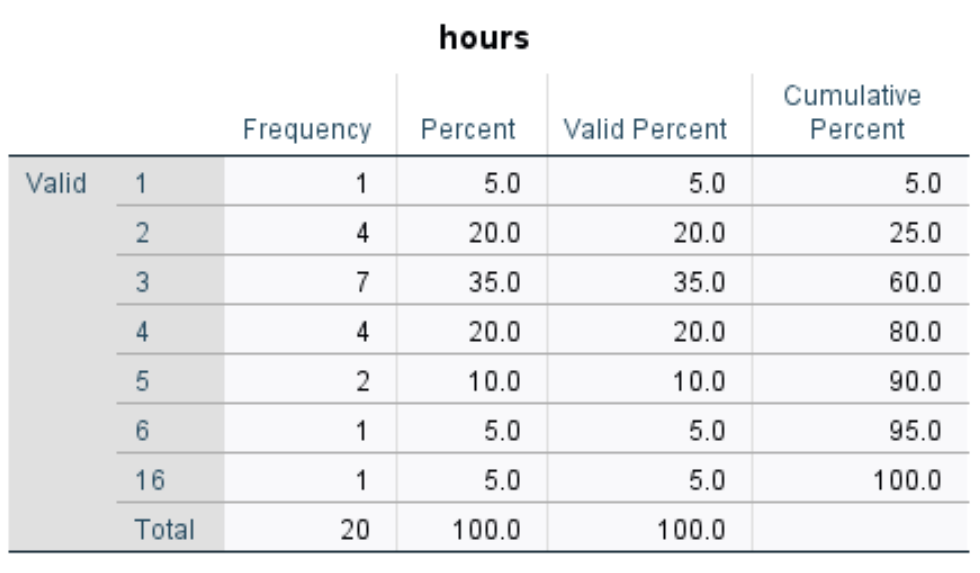
The way to interpret the table is as follows:
- The first column displays each unique value for the variable hours. In this case, the unique values are 1, 2, 3, 4, 5, 6, and 16.
- The second column displays the frequency of each value. For example, the value 1 appears 1 time, the value 2 appear 4 times, and so on.
- The third column displays the percent for each value. For example, the value 1 makes up 5% of all values in the dataset. The value 2 makes up 20% of all values in the dataset, and so on.
- The last column displays the cumulative percent. For example the values 1 and 2 make up a cumulative 25% of the total dataset. The values 1, 2, and 3 make up a cumulative 60% of the dataset, and so on.
This table gives us a nice idea about the distribution of the data values for each variable.
Graphs
Graphs also help us understand the distribution of data values for each variable in a dataset. One of the most popular graphs for doing so is a histogram.
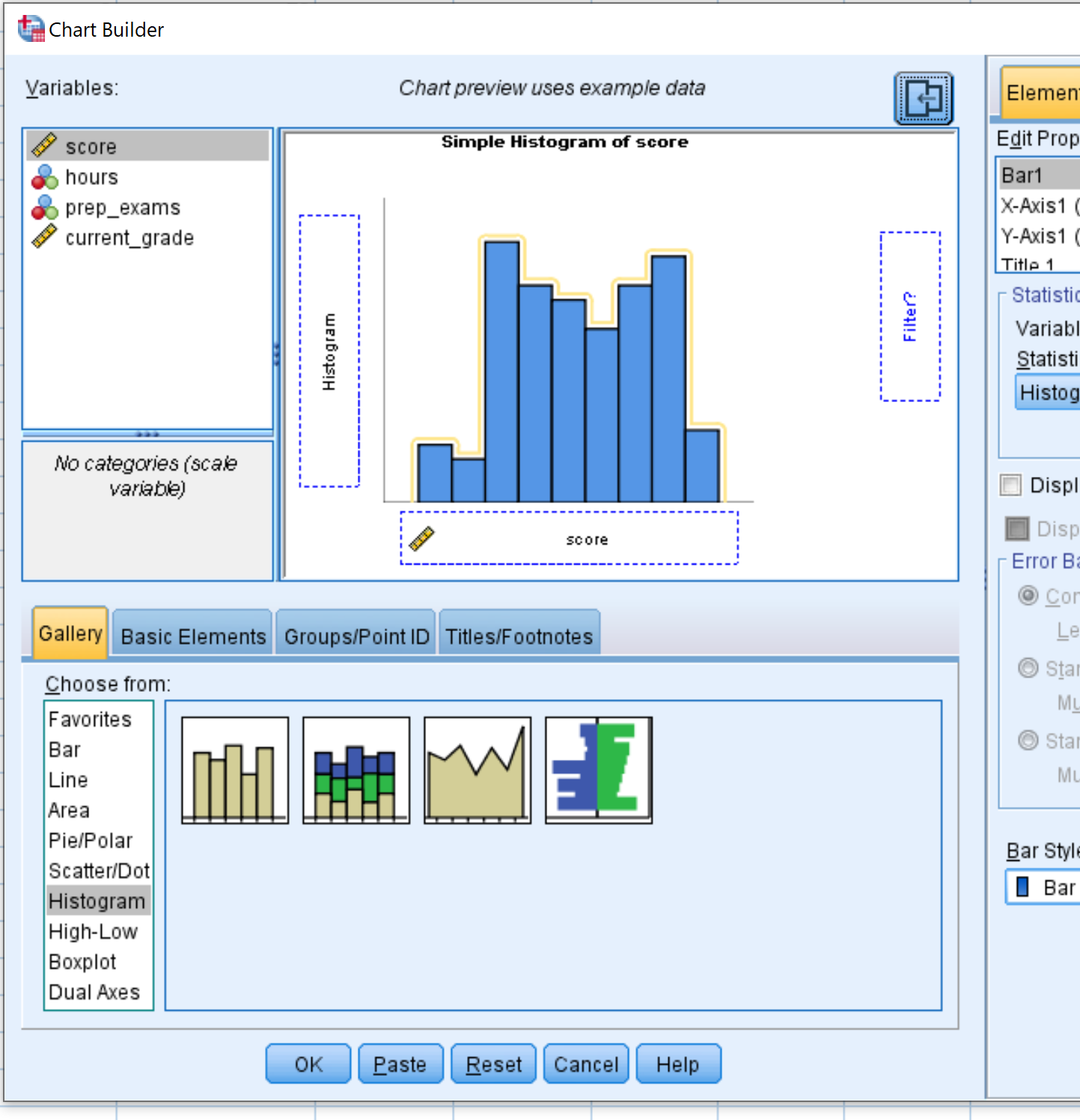
To create a histogram for a given variable in a dataset, click the Graphs tab, then Chart Builder.
In the new window that pops up, choose Histogram from the “Choose from” panel. Then drag the first histogram option into the main editing window. Then drag your variable of interest onto the x-axis. We’ll use score for this example. Then click OK.
Once you click OK, a histogram will appear that displays the distribution of values for the variable score:
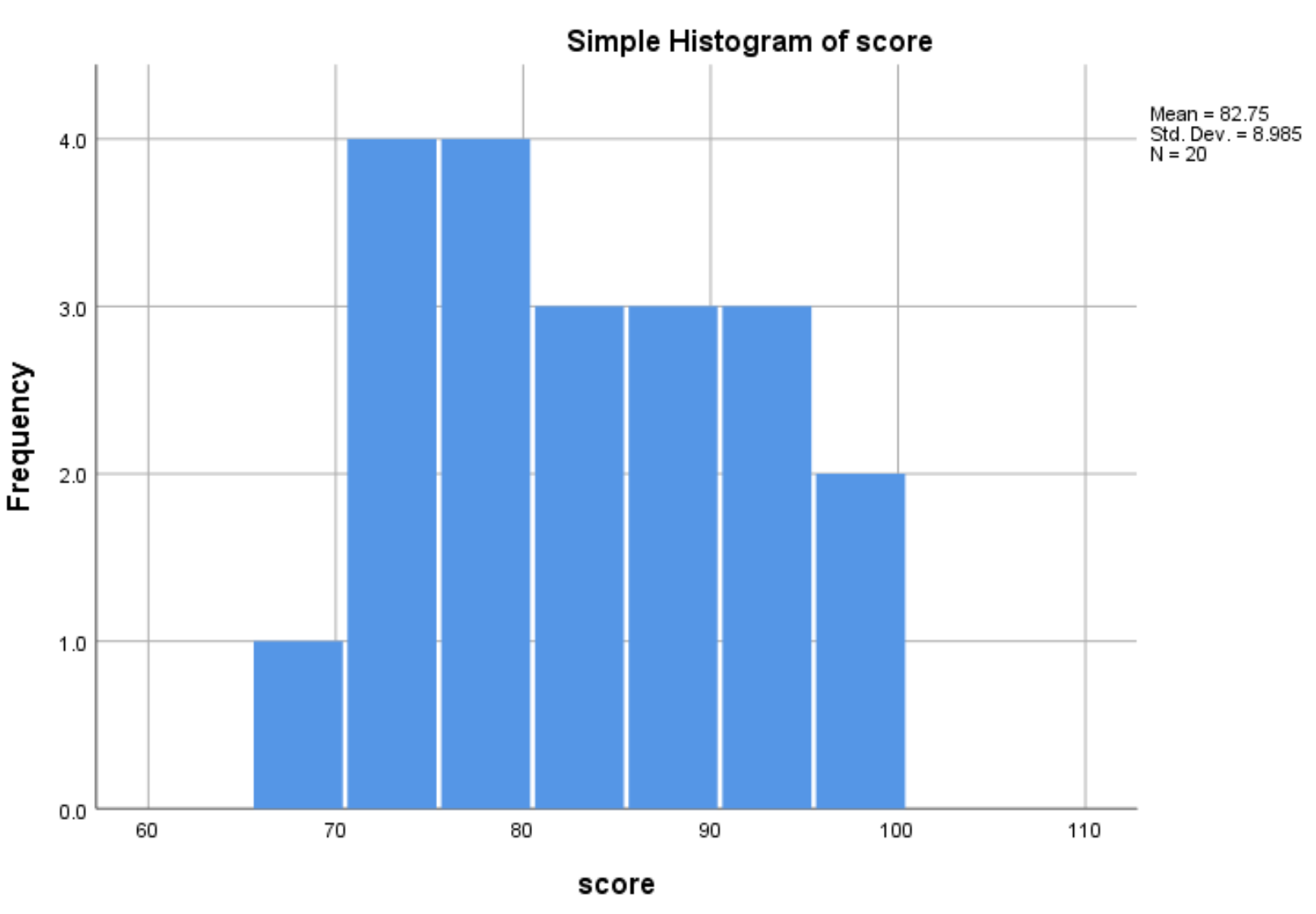
From the histogram we can see that the range of exam scores varies between 65 and 100, with most of the scores being between 70 and 90.
We can repeat this process to create a histogram for each of the other variables in the dataset as well.