You can use the following basic syntax to set the column names of a DataFrame when importing a CSV file into pandas:
colnames = ['col1', 'col2', 'col3'] df = pd.read_csv('my_data.csv', names=colnames)
The names argument takes a list of names that you’d like to use for the columns in the DataFrame.
By using this argument, you also tell pandas to use the first row in the CSV file as the first row in the DataFrame instead of using it as the header row.
The following example shows how to use this syntax in practice.
Example: Set Column Names when Importing CSV File into Pandas
Suppose we have the following CSV file called players_data.csv:
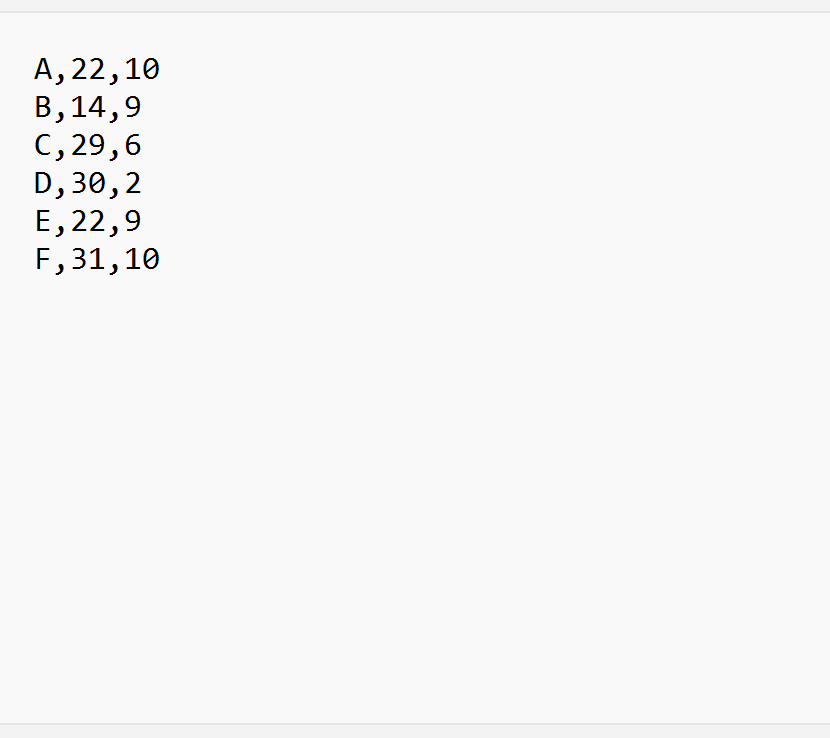
From the file we can see that the first row does not contain any column names.
If we import the CSV file using the read_csv() function, pandas will attempt to use the values in the first row as the column names for the DataFrame:
import pandas as pd #import CSV file df = pd.read_csv('players_data.csv') #view resulting DataFrame print(df) A 22 10 0 B 14 9 1 C 29 6 2 D 30 2 3 E 22 9 4 F 31 10
However, we can use the names argument to specify our own column names when importing the CSV file:
import pandas as pd #specify column names colnames = ['team', 'points', 'rebounds'] #import CSV file and use specified column names df = pd.read_csv('players_data.csv', names=colnames) #view resulting DataFrame print(df) team points rebounds 0 A 22 10 1 B 14 9 2 C 29 6 3 D 30 2 4 E 22 9 5 F 31 10
Notice that the first row in the CSV file is no longer used as the header row.
Instead, the column names that we specified using the names argument are now used as the column names.
Note: You can find the complete documentation for the pandas read_csv() function here.
Additional Resources
The following tutorials explain how to perform other common tasks in Python:
Pandas: How to Skip Rows when Reading CSV File
Pandas: How to Append Data to Existing CSV File
Pandas: How to Use read_csv with usecols Argument