One of the most common ways to assess the performance of a classification model is to create a confusion matrix, which summarizes the predicted outcomes from the model vs. the actual outcomes from the dataset.
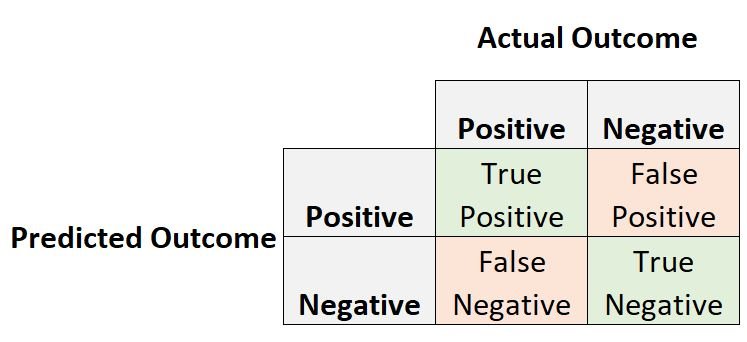
Two metrics that we’re often interested in within a confusion matrix are positive predictive value and sensitivity.
Positive predictive value is the probability that an observation with a positive predicted outcome actually has a positive outcome.
It is calculated as:
Positive predictive value = True Positives / (True Positives + False Positives)
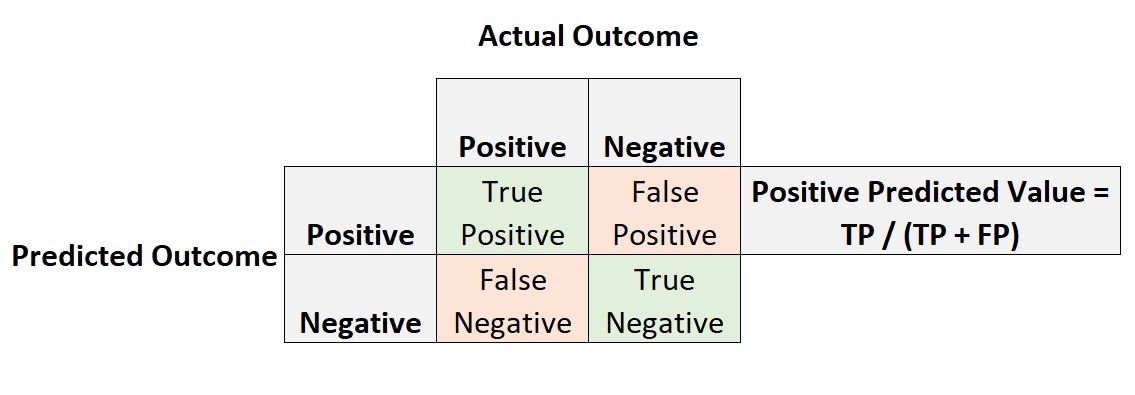
Sensitivity is the probability that an observation with a positive outcome actually has a positive predicted outcome.
It is calculated as:
Sensitivity = True Positives / (True Positives + False Negatives)

The following example shows how to calculate both of these metrics in practice.
Example: Calculating Positive Predictive Value & Sensitivity
Suppose a doctor uses a logistic regression model to predict whether or not 400 individuals have a certain disease.
The following confusion matrix summarizes the predictions made by the model:
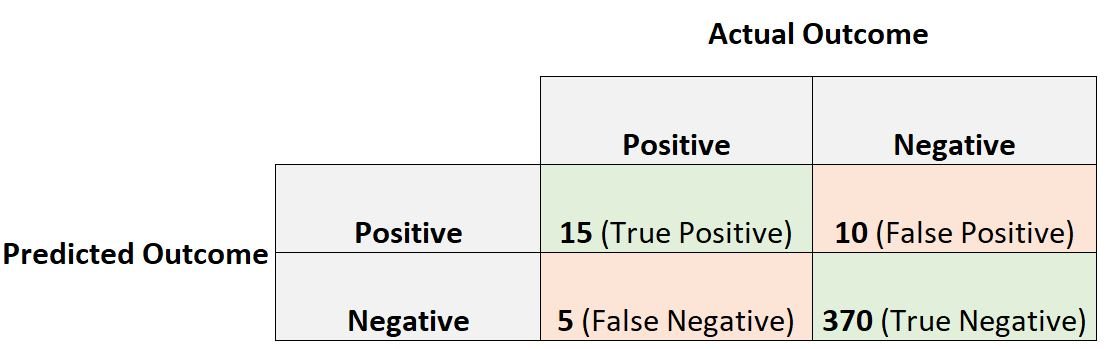
We would calculate the positive predictive value as:
- Positive predictive value = True Positives / (True Positives + False Positives)
- Positive predictive value = 15 / (15 + 10)
- Positive predictive value = 0.60
This tells us that the probability that an individual who receives a positive test result actually has the disease is 0.60.
We would calculate the sensitivity as:
- Sensitivity = True Positives / (True Positives + False Negatives)
- Sensitivity = 15 / (15 + 5)
- Sensitivity = 0.75
This tells us that the probability that an individual who has the disease will actually receive a positive test result is 0.75.
Additional Resources
The following tutorials explain how to create a confusion matrix in different statistical software:
How to Create a Confusion Matrix in Excel
How to Create a Confusion Matrix in R
How to Create a Confusion Matrix in Python