A statistical hypothesis is an assumption about a population parameter. For example, we may assume that the mean height of a male in a certain county is 68 inches. The assumption about the height is the statistical hypothesis and the true mean height of a male in the U.S. is the population parameter.
A hypothesis test is a formal statistical test we use to reject or fail to reject a statistical hypothesis. To perform a hypothesis test, we obtain a random sample from the population and determine if the sample data is likely to have occurred, given that the null hypothesis is indeed true.
If the sample data is sufficiently unlikely under that assumption, then we can reject the null hypothesis and conclude that an effect exists.
The way we determine whether or not the sample data is “sufficiently unlikely” under the assumption that the null is true is to define some significance level (typically chosen to be 0.01, 0.05, or 0.10) and then check to see if the p-value of the hypothesis test is less than that significance level.
If the p-value is less than the significance level, then we say that the results are statistically significant. This simply means that some effect exists, but it does not necessarily mean that the effect is actually practical in the real world. Results can be statistically significant without being practically significant.
Related: An Explanation of P-Values and Statistical Significance
Practical Significance
It’s possible for hypothesis tests to produce results that are statistically significant, despite having a small effect size. There are two main ways that small effect sizes can produce small (and thus statistically significant) p-values:
1. The variability in the sample data is very low. When your sample data has low variability, a hypothesis test is able to produce more precise estimates of the population’s effect, which allows the test to detect even small effects.
For example, suppose we want to perform an independent two-sample t test on the following two samples that show the test scores of 20 students from two different schools to determine if the mean test scores are significantly different between the schools:
sample 1: 85 85 86 86 85 86 86 86 86 85 85 85 86 85 86 85 86 86 85 86 sample 2: 87 86 87 86 86 86 86 86 87 86 86 87 86 86 87 87 87 86 87 86
The mean for sample 1 is 85.55 and the mean for sample 2 is 86.40 . When we perform an independent two-sample t test, it turns out that the test statistic is -5.3065 and the corresponding p-value is <.0001>. The difference between the test scores is statistically significant.
The difference between the mean test scores for these two samples is only 0.85, but the low variability in test scores for each school causes a statistically significant result. Note that the standard deviation for the scores is 0.51 for sample 1 and 0.50 for sample 2.
This low variability is what allowed the hypothesis test to detect the tiny difference in scores and allow the differences to be statistically significant.
The underlying reason that low variability can lead to statistically significant conclusions is because the test statistic t for a two sample independent t-test is calculated as:
test statistic t = [ (x1 – x2) – d ] / (√s21 / n1 + s22 / n2)
where s21 and s22 indicate the sample variation for sample 1 and sample 2, respectively. Notice that when these two numbers are small, the entire denominator of the test statistic t is small.
And when we divide by a small number, we end up with a large number. This means the test statistic t will be large and the corresponding p-value will be small, thus leading to statistically significant results.
2. The sample size is very large. The larger the sample size, the greater the statistical power of a hypothesis test, which enables it to detect even small effects. This can lead to statistically significant results, despite small effects that may have no practical significance.
For example, suppose we want to perform an independent two-sample t test on the following two samples that show the test scores of 20 students from two different schools to determine if the mean test scores are significantly different between the schools:
Sample 1: 88 89 91 94 87 94 94 92 91 86 87 87 92 89 93 90 92 95 89 93 Sample 2: 95 88 93 87 89 90 86 90 95 89 91 92 91 88 94 93 94 87 93 90
If we create a boxplot for each sample to display the distribution of scores, we can see that they look very similar:
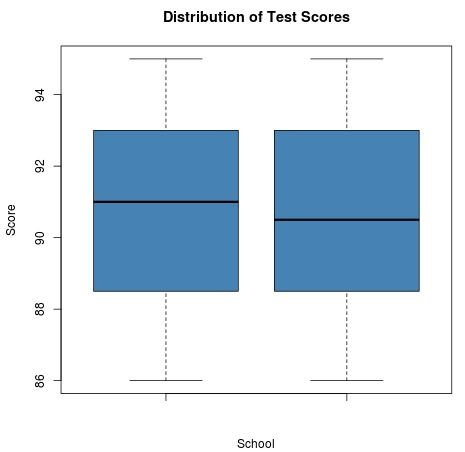
The mean for sample 1 is 90.65 and the mean for sample 2 is 90.75. The standard deviation for sample 1 is 2.77 and the standard deviation for sample 2 is 2.78. When we perform an independent two-sample t test, it turns out that the test statistic is -0.113 and the corresponding p-value is 0.91. The difference between the mean test scores is not statistically significant.
However, consider if the sample sizes of the two samples were both 200. In this case, an independent two-sample t test would reveal that the test statistic is -1.97 and the corresponding p-value is just under 0.05. The difference between the mean test scores is statistically significant.
The underlying reason that large sample sizes can lead to statistically significant conclusions once again goes back to the test statistic t for a two sample independent t-test:
test statistic t = [ (x1 – x2) – d ] / (√s21 / n1 + s22 / n2)
Notice that when n1 and n2 are small, the entire denominator of the test statistic t is small. And when we divide by a small number, we end up with a large number. This means the test statistic t will be large and the corresponding p-value will be small, thus leading to statistically significant results.
Using Subject Matter Expertise to Assess Practical Significance
To determine whether a statistically significant result from a hypothesis test is practically significant, subject matter expertise is often needed.
In the previous examples when we were testing for differences between test scores for two schools, it would help to have the expertise of someone who works in schools or who administers these types of tests to help us determine whether or not a mean difference of 1 point has practical implications.
For example, a mean difference of 1 point may be statistically significant at alpha level = 0.05, but does this mean that the school with the lower scores should adopt the curriculum that the school with the higher scores is using? Or would this involve too much administrative cost and be too expensive/timely to implement?
Just because there is a statistically significant difference in test scores between two schools does not mean that the effect size of the difference is big enough to enact some type of change in the education system.
Using Confidence Intervals to Assess Practical Significance
Another useful tool for determining practical significance is a confidence interval. A confidence interval gives us a range of values that the true population parameter is likely to fall in.
For example, let’s go back to the example of comparing the difference in test scores between two schools. A principal may declare that a mean difference in scores of at least 5 points is needed in order for the school to adopt a new curriculum.
In one study, we may find that the mean difference in test scores is 8 points. However, the confidence interval around this mean may be [4, 12], which indicates that 4 could be the true difference between the mean test scores. In this case, the principal may conclude that the school will not change the curriculum since the confidence interval indicates that the true difference could be less than 5.
However, in another study we may find that the mean difference in test scores is once again 8 points, but the confidence interval around the mean may be [6, 10]. Since this interval does not contain 5, the principal will likely conclude that the true difference in test scores is greater than 5 and thus determine that it makes sense to change the curriculum.
Conclusion
In closing, here’s what we learned:
- Statistical significance only indicates if there is an effect based on some significance level.
- Practical significance is whether or not this effect has practical implications in the real world.
- We use statistical analyses to determine statistical significance and subject-area expertise to assess practical significance.
- Small effect sizes can produce small p-values when (1) the variability in the sample data is very low and when (2) the sample size is very large.
- By defining a minimum effect size before we conduct a hypothesis test, we can better assess whether the result of a hypothesis test (even if it’s statistically significant) actually has real world practicality.
- Confidence intervals can be useful for determining practical significance. If the minimum effect size is not contained within a confidence interval, then the results may be practically significant.