You can use the following basic syntax to skip specific columns when importing an Excel file into a pandas DataFrame:
#define columns to skip skip_cols = [1, 2] #define columns to keep keep_cols = [i for i in range(4) if i not in skip_cols] #import Excel file and skip specific columns df = pd.read_excel('my_data.xlsx', usecols=keep_cols)
This particular example will skip columns in index positions 1 and 2 when importing the Excel file called my_data.xlsx into pandas.
The following example shows how to use this syntax in practice.
Example: Skip Specific Columns when Importing Excel File into Pandas
Suppose we have the following Excel file called player_data.xlsx:
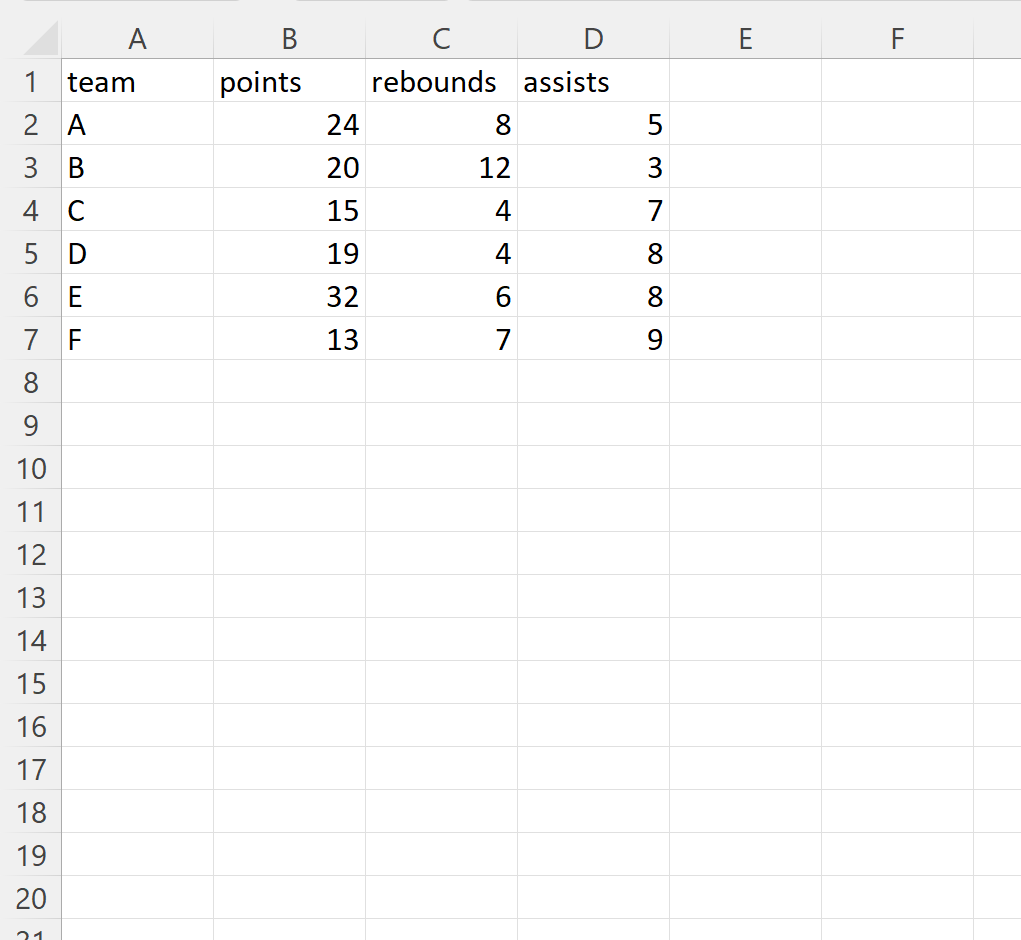
We can use the following syntax to import this file into a pandas DataFrame and skip the columns in index positions 1 and 2 (the points and rebounds columns) when importing:
#define columns to skip skip_cols = [1, 2] #define columns to keep keep_cols = [i for i in range(4) if i not in skip_cols] #import Excel file and skip specific columns df = pd.read_excel('player_data.xlsx', usecols=keep_cols) #view DataFrame print(df) team assists 0 A 5 1 B 3 2 C 7 3 D 8 4 E 8 5 F 9
Notice that all columns in the Excel file except for the columns in index positions 1 and 2 (the points and rebounds columns) were imported into the pandas DataFrame.
Note that this method assumes you know how many columns are in the Excel file beforehand.
Since we knew that there were 4 total columns in the file, we used range(4) when defining which columns we wanted to keep.
Note: You can find the complete documentation for the pandas read_excel() function here.
Additional Resources
The following tutorials explain how to perform other common tasks in pandas:
Pandas: How to Skip Rows when Reading Excel File
Pandas: How to Specify dtypes when Importing Excel File
Pandas: How to Combine Multiple Excel Sheets